Measuring with Big Data
What can you measure with a data set that was not originally intended to measure anything? This was the subject of a meeting in April 2011 at Boston City Hall between a handful of researchers from the Boston Area Research Initiative (BARI; including myself) and members of the Mayor’s Office of New Urban Mechanics and the City’s performance management team. The data set of interest was the extensive corpus of records (more than 300,000 at that time) that had been generated by the City’s relatively young 311 system.
We had no lack of ideas. The problem was that our two main ideas were mutually incompatible. First, there was the possibility that the data acted as the “eyes and ears of the city” and could enable measures of deterioration and dilapidation (also known as physical disorder or “broken windows”) across neighborhoods. The second idea was that they gave us an insight into how constituents engaged with government services. But if the data were a pure reflection of either of these two things, it could not be the other. That is, if 311 perfectly communicated current conditions, then constituent engagement was robust and consistent across the city, and thus not worth measuring; and if it exactly reflected constituent engagement, then those tendencies would obscure the ability to “see” objective conditions. Obviously, the data reflected a combination of objective conditions and subjective patterns of engagement, meaning the two interpretations of the data seemed hopelessly entangled. And yet, in the months that followed, we solved the problem. BARI now releases annual metrics drawn from 311 data for both physical disorder and custodianship, or the tendency of a community to take care of public spaces (Figure 6.1).
The problem of measurement is not unique to 311 reports but is a general weakness of administrative data, social media, and the other “naturally occurring data” that drive urban informatics . Because these data were not created for the purposes of research they lack many of the features that we often take for granted in traditional data. What is it that they measure? Do the data capture what they appear to, or do they suffer from biases? What are the units of measurement (i.e., people?, neighborhoods?) that we can describe and how often (i.e., monthly?, annually?)? Answering such questions is an early step in unlocking the potential of a given data set. This chapter will focus on the conceptual tools that enable such efforts to develop original measures from novel data sets. As the first chapter in the unit on Measurement, it will also set the stage for the subsequent chapters, in which we will create and further work with new measures.
Worked Example and Learning Objectives
This chapter is unique in this book, as it will focus entirely on conceptual skills—you will not need to open RStudio once! We will walk through the process that my colleagues and I undertook to make sense of the 311 data to generate measures that describe neighborhoods, but it is applicable to any naturally occurring data set and unit of analysis you might encounter. Along the way, we will learn to:
- Describe the “missing ingredients” of naturally occurring data;
- Specify the desired unit of analysis for measurement;
- Leverage the schema or organization of a data set to access the desired unit of analysis;
- Identify concepts that might be measured through a data set;
- Isolate the desired content to pursue a given measurement;
- Identify potential biases in the data and propose ways of addressing them.
Link: Though this chapter does not work through an example in R, you might be interested in visiting BARI’s Boston Data Portal, where the 311 metrics described here are published annually: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/CVKM87 (or go to the crime and disorder page on the interactive map: https://experience.arcgis.com/experience/ce3975f9368841f791d1fc8891e6171b).
Note that there will be regular references to technical steps that must be taken to create a measure, especially aggregation of records and the merger of data sets. We have not learned how to do these skills yet. Not to worry, however, as we will learn all about them in Chapter 7. For now, we are just going to discuss them conceptually.
Data and Theory: The Responsibility of the Analyst
Before describing the missing ingredients of naturally occurring data, it is useful to reflect on the responsibility the analyst has when deciding how to properly use a data set. This speaks to a rather contentious debate that has arisen following the emergence of big data. In 2008, Chris Anderson, editor of WIRED magazine, wrote an essay presaging “The End of Theory” (Anderson 2008). He argued that “with enough data, the numbers speak for themselves.” In his view there is no longer any need for theory. The data will guide us through the questions that need to be asked and answered, and analysts just need to be capable of following along.
Needless to say, Anderson’s essay has attracted numerous critics. One of my favorite retorts was from Massimo Pigliucci, a philosopher of biology, who argued that Anderson misses that the very purpose of science is to explain why things work the way they do (Pigliucci 2009). The same knowledge of “why” is necessary for practitioners and policymakers to do their jobs and for companies to develop effective products. If we do not understand the meaning of the questions elicited by data, the answers will be useless to us. Pigliucci also encourages Anderson to recall the maxim, “there are no data without theory.” Without some theory or model of the world, one has no basis for determining which data to collect or how to interpret them. Every decision that an analyst makes when working with data, from data cleaning to variable construction to model specification, is based on the knowledge, assumptions, and goals they bring to the data. To claim otherwise is to ignore the agency that the analyst brings to the data and the responsibility they hold for framing, interpreting, and communicating the results. Whether we call it “theory” or not, awareness of these concerns is critical to a well-informed analysis. This perspective has been a major thrust throughout this book and will be especially important as we start to design new measures.
Missing Ingredients of Naturally Occurring Data
Naturally occurring data were not collected according to a systematic research protocol but as the byproduct of some administrative or technological process. As such, the analyst must grapple with three “missing ingredients” that are traditionally baked into data collection processes.
- What units of analysis can be described? Most naturally occurring data sets consist of records. They might reference units of analysis, such as neighborhoods or individuals, but describing them requires the composite analysis of all of the records together. First, the analyst must determine what the options are and which are of interest.
- What can the data measure? This is a deceptively simple question. Often the answer is “lots of stuff,” which can create additional complications. It is up to the analyst to decide which aspect or aspects of the desired unit of analysis are of interest and how to isolate the relevant information from the rest of the data set’s content.
- Are the data biased (and what to do about it)? An administrative system or online platform might capture all cases associated with it, but this is not a guarantee that that information is a comprehensive reflection of all related information. Does it capture all of the events it purports to? Do some demographic groups avail themselves of a service more than others, creating an unbalanced view? What other aspects of the data-generation process might introduce biases into the data?
How well these three questions are answered will determine the usefulness of any measure based on naturally occurring data. The remainder of this chapter will walk through them in turn.
Unit of Analysis
In Unit I, we learned how to create new variables, or measures (or indicators, metrics, etc.). But those variables were either additional descriptors of individual records or summations of records. What if we want to describe a person, place, or thing referenced in the data set, or event to analyze all of the people, places, or things referenced in the data set? We would need to aggregate the records to a particular unit of analysis. Before we can do that, we need to know what units of analysis are available to us and to select from them the one that would best further our goals. An important tool for doing this is the schema, or organizational blueprint of how a data set’s structure relates to other data sets at various levels of analysis.
Schema
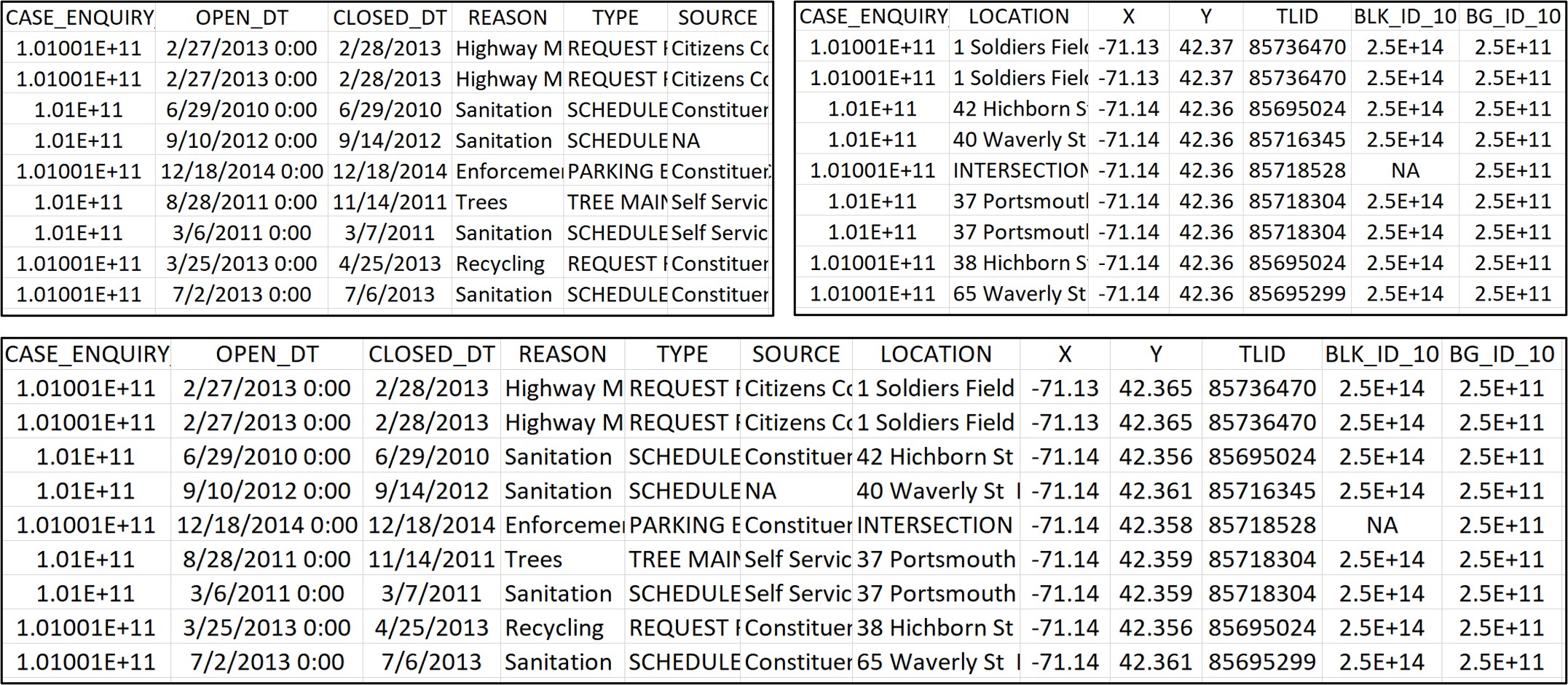
A schema is an organizational blueprint not only for a single data set but for a series of related data sets. It is most often used in database management because databases often contain multiple datasets that link to each other on specific key variables, also known as unique identifiers. Sometimes the data sets within a database contain separate sets of variables all referring to the same unit of analysis to limit the number of variables in any single data set. For example, Figure 6.2 contains two different sets of variables describing Boston’s 311 cases: one set describes the features of the event (date of report, case type, etc.); the other describes the geographic location of each case. These can be kept apart or merged on the CASE_ENQUIRY variable, which is the unique identifier for records.
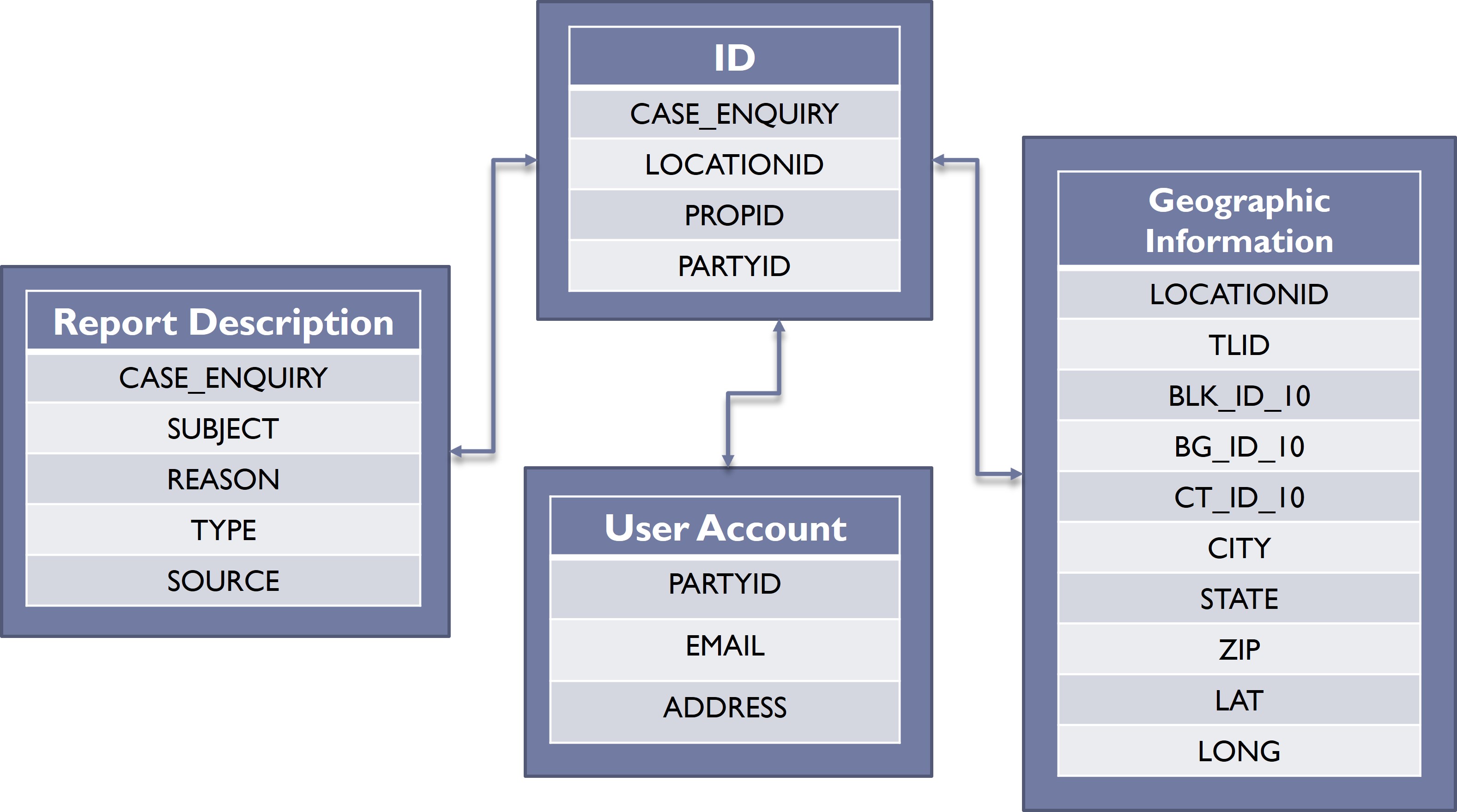
A data set might also include variables that are the primary units of analysis in another data set, enabling linkage between them. This is apparent in Figure 6.3, which represents a more complex set of relationships between Boston’s 311 records and other data sets. A fundamental ID data set is simply the list of cases, with the unique identifier of CASE_ENQUIRY. This unique identifier also links to the Report Description data set, which contains additional information on the case itself. The relationship between these two data sets is similar to that illustrated in Figure 6.2.
The ID data set contains two additional unique identifiers, though, that link it to other data sets with distinct units of analysis. First, the variable LOCATIONID is a unique identifier for all addresses and intersections in Boston that links to a separate Geographic Information data set. This data set is a list of all possible values for LOCATIONID with additional information on the location of each, including its street segment (TLID), census geographies (BLK_ID_10, BG_ID_10, CT_ID_10), its CITY, STATE, ZIP code, and LAT and LONG. Also, the variable PARTYID is the unique identifier for User Account. Users of the 311 system can create an account for tracking their cases and enabling the city to contact them by EMAIL or mailing ADDRESS. Again, this is all represented graphically in 6.3.
A schema like this one enables us to do two things. One is to merge information across data sets, for example bringing in additional geographic information associated with the address or intersection referenced in each record, as we have already done. The other is the ability to aggregate records to describe the units of analysis that they reference. For instance, we might count the number of cases referencing every address and intersection in the city, or the number of cases made by every user of the system. Thinking bigger, we might use the information contained in those cases to develop any number of measures describing addresses or users.
What We Did: Defining “Neighborhood”
The goal of me and my colleagues when approaching the 311 data set was to describe the conditions of neighborhoods. Such measures have a long intellectual history and are referred to as ecometrics, as they quantify the physical and social characteristics (-metrics) of a space (eco-). Though they have been traditionally measured with resident surveys and neighborhood audits known as systematic social observation (think the Google StreetView car replaced by people walking with clipboards), we believed there was an opportunity to achieve the same goal using 311. To do this we had to capitalize on 311’s schema (as illustrated in 6.3) and the linkage between records and geographic information.
Geography is a great example of an extended schema because it has so many scales of organization. To facilitate the analysis of the 311 data and related data sources describing Boston, BARI developed a database we call the Geographical Infrastructure for the City of Boston (GI), which we curate and update annually. The GI compiles and connects the places and regions of the city at multiple levels: discrete locations, including properties, which are contained in land parcels, and intersections; street segments; census geographies (i.e., blocks, block groups, and tracts); and broad administrative regions (e.g., planning districts, neighborhood statistical areas, election wards, districts for public health, police, fire, and public works). Importantly, these different scales are nested within each other. Properties are contained in land parcels, which sit on streets and inside census geographies. Census geographies are designed to have blocks sit within block groups and block groups sit within tracts. The smaller census geographies are generally contained within the City’s administrative regions. The database reflects this, with every property having a variable for its land parcel, every land parcel having variables for its street and census block, and so on.
311 records come with a LOCATIONID, which links to land parcels. We wanted to measure the characteristics of neighborhoods, which are often approximated with census geographies. Thus, we needed to link with the data set of land parcels, which includes variables for all three census geographies. We were then able to aggregate to any of these geographic scales we wanted. Depending on the goals of an analysis, our preference might be for census block groups or tracts. Thus, we did both (and have since published metrics for both annually).
Isolating Relevant Content
You have probably taken many surveys in your life. Maybe as part of a psychology course or a doctor’s visit or a public poll or a BuzzFeed quiz. Typically, a survey consists of dozens of questions. These questions are not randomly selected, however, nor does the person who designed that survey see them as discrete pieces of information. They are organized into groupings intended to capture specific constructs, like personality traits, health behaviors, political leanings, etc.
Like a traditional survey, naturally occurring data also contain lots of content, often far outstripping those dozens of questions. For instance, the 311 system in Boston has over 250 case types ranging from pick-ups for large trash items to downed trees to needle cleanup to cracked sidewalks. Though these diverse case types are unified in their need for government services, they describe many, many different aspects of the urban landscape. But unlike the survey they do not come equipped with any pre-established constructs for what they can measure. In other words, we do not really know what the “eyes and ears of the city” are seeing, hearing, and communicating about the urban landscape. Consequently, an analyst working with this or any other naturally occurring data sets needs to determine what they want to measure and how to isolate that information from all of the other content contained in the data.
Latent Constructs: A Guide for Measurement
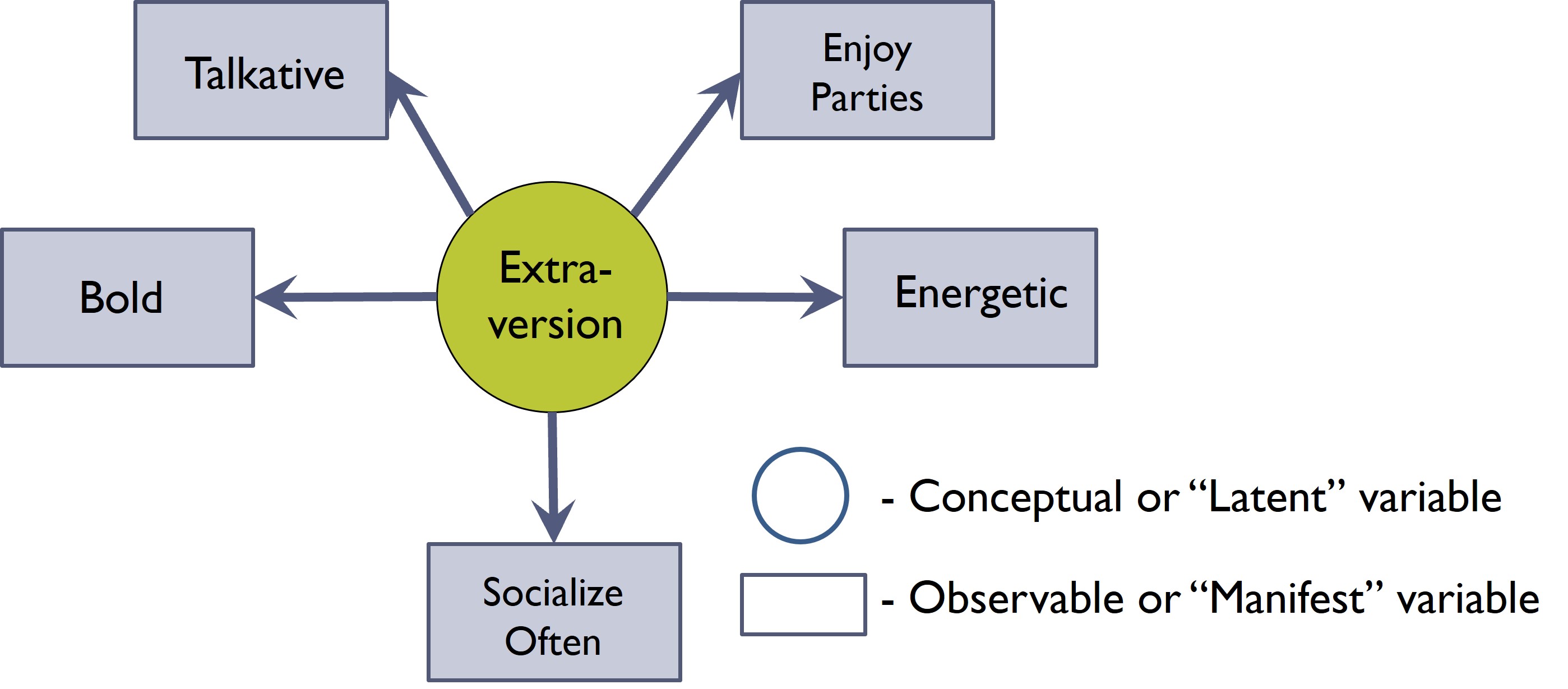
To guide our approach to measurement, we will borrow a concept from psychology called the latent construct model. It is based in the philosophical assumption that the things we truly want to know about a person, place, or thing are underlying tendencies and propensities that are impossible to directly access. Instead, we have to infer them from the behaviors, events, and patterns that we can observe. In short, these underlying latent constructs are what we want to measure, but to do so we must quantify the manifest variables that are symptoms or reflections of these latent constructs in action.
Stepping away from urban informatics for a moment, let us take a classic example from personality psychology that will likely be familiar. Extraversion is a personality trait that has been measured for nearly a century, but you would not necessarily ask someone, “How extraverted are you?” Instead, as illustrated in Figure 6.4, a survey on extraversion might include items about being “talkative,” “energetic,” “bold,” and “outgoing,” or “enjoying parties”. An observational measure might look for similar features. The combination of these discrete manifest variables then gives rise to a measure that reflects the latent construct we wanted to observe in the first place.
The latent construct model is a helpful tool for thinking about how we might extract information from naturally occurring data, though the process is a bit reversed from traditional survey development. Researchers developing surveys define a latent construct and then write items that can act as the manifest variables that capture that latent construct. Analysts working with naturally occurring data are presented with a multitude of manifest variables already present in the data. They must determine which of these represent their latent construct of interest (and which should be ignored). In either case, however, the process begins by defining the latent construct and the kinds of ways it might be manifest.
What We Did: Isolating Physical Disorder
A large proportion of 311 records reference the deterioration and denigration of spaces and structures, including loose garbage, graffiti, and dilapidation. These reflect “physical disorder,” a popular concept (or latent construct) often measured in urban science and of interest to sociologists, criminologists, public health researchers, and others. The 311 data set would then appear to provide many manifest variables for measuring the tendency of a community to generate or suffer from physical disorder. The challenge that faced our project, however, was twofold: identifying those case types and separating them out from all the other case types in the data set that have little bearing on physical disorder.
When we originally started working with the data in 2011, there were “only” 178 case types present in the data. I personally read through these one-by-one, identifying 33 that might be evidence of either denigration or neglect to spaces and structures. Importantly, we did not include instances of natural deterioration, like potholes or street light outages, or personal requests regarding things like street sweeping schedules or a special pick-up of a large trash item (e.g., couch). Many of the case types we identified were traditionally included in observational protocols for measuring physical disorder, such as graffiti and abandoned buildings. Others were unfamiliar but seemingly relevant, like cars illegally parked on a lawn. In these cases the data set’s rich content made novel information available. Most notably, 311 was able to “see” the conditions inside private spaces, including failing utilities and rodent infestations. Though this diversity of manifest variables for measuring physical disorder was impressive, it is important to note that they constituted fewer than 20% of case types and about 50% of all reports. Thus, we had to discard over half of the database to isolate our desired construct. If we had simply summed cases across neighborhoods, we would have measured something very different and probably entirely uninterpretable.
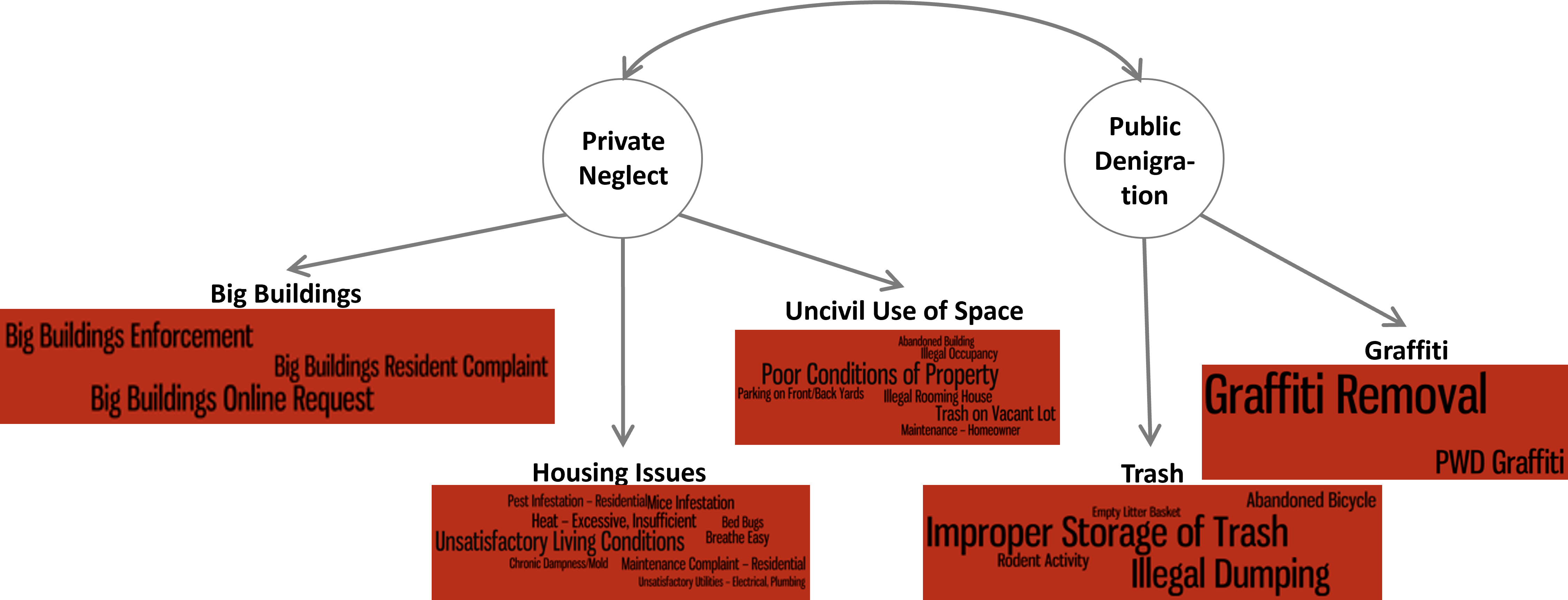
Thirty-three is a large number of manifest variables. And as we looked closely at them, it seemed like there might be some important sub-categories, for instance, differentiating between disorder in private and public spaces. We tabulated the number of cases in each of these 33 cases for all census block groups and looked closely at their correlations using a technique called factor analysis (an advanced technique that goes beyond the scope of this book). Given the content of the cases and the results of this analysis, we confirmed that there were two distinct but related aspects of physical disorder: private neglect and public denigration. These further broke down into five more specific categories: housing, uncivil use of space, and big buildings for private neglect; and graffiti and trash for public denigration. (Note that these final measures only used 28 of the 33 case types that we originally identified as we determined that five of the case types were not as relevant as we thought.) This constituted a multi-dimensional measure of physical disorder that was more nuanced than any survey or observational protocol that preceded it. This is illustrated in Figure 6.5. That said, it still begged the question of whether the 311 system measured these conditions faithfully, or if they were biased in some way.
Biases and Validity
It is tempting to treat administrative records, social media posts, and other forms of naturally occurring data as faithful representations of the pulse of the city . Once one isolates the content that reflects a particular construct of interest, a new dimension of the urban landscape should be lain bare. But the data were not collected systematically with the goal of capturing objective information. Instead, aspects of the data-generation process may imbue the data with inherent biases, confounding any measures based on them. Especially in the case of crowdsourced content, like 311 reports and social media posts, there are questions about how often people of different backgrounds and perspectives are contributing content, and the kinds of things they see as worth contributing. This brings us back to the original challenge my colleagues and I faced at the beginning of this chapter: are 311 reports a reflection of objective issues or the tendency of community members to report issues? As such, analysts working with naturally occurring data must identify the potential sources of bias and account for them in some way.
Validity
Researchers are often concerned with the validity of their measures, defined as the extent to which it reflects the real-world features that they are intended to capture. The reason why should be apparent: a measure that does not actually reflect what it is supposed to is not especially useful. Survey measures of extraversion should accurately assess extraversion. Standardized tests should accurately evaluate ability in mathematics and language arts. Ecometrics should accurately quantify the physical and social characteristics of neighborhoods.
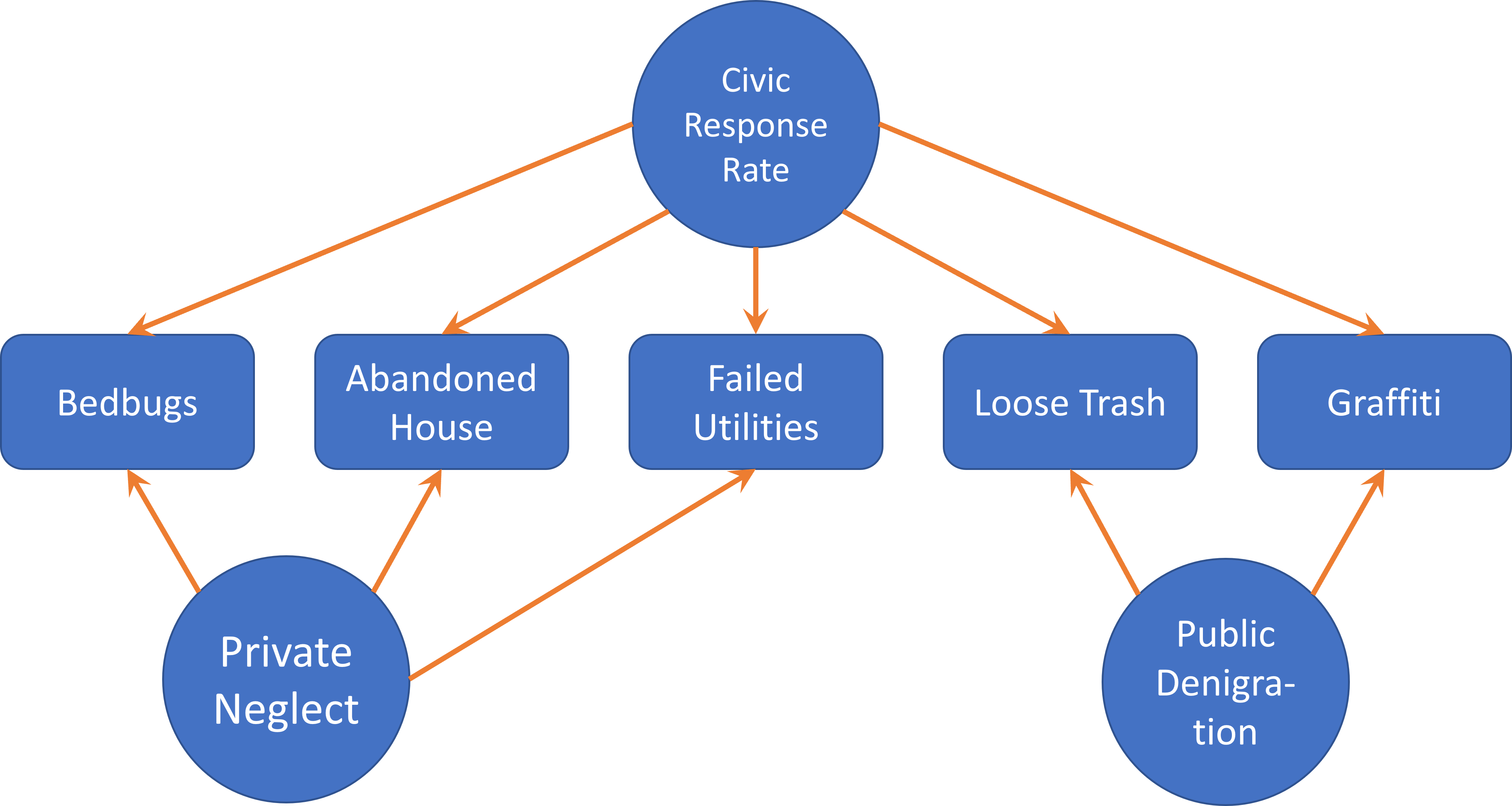
Evaluating validity might be split into statistical and non-statistical techniques. Non-statistical techniques are primarily conceptual and include face validity, or whether a measure appears on its surface to measure the construct of interest, and content validity, or whether a measure covers the range of information associated with a construct (but nothing more). In a sense, we have already engaged in an exercise of non-statistical validity in Section 6.6) as we defined the manifest variables that might capture a given latent construct. An extension of this reasoning is to consider whether one or more manifest variables might arise from more than one latent construct. For instance, as shown in Figure 6.6, 311 reports are a product of both objective conditions and the decision of local residents to report those conditions to the government, or what we might refer to as a “civic response rate.” Similarly, a researcher with social media data often has to develop ways of removing posts made by automated “bots,” or distinguishing posts made by individuals from those made by organizations.
Statistical techniques for establishing validity are varied but often entail either convergent validity or discriminant validity. Both involve coordinating the measures of interest with external measures already believed to be valid. In the former, the analyst examines whether the newly developed measure agrees with one or more measures that capture similar constructs. For instance, does an IQ test predict academic performance? Does the volume of Twitter posts correlate with population numbers across neighborhoods? Does a measure of physical disorder derived from 311 records agree with observations made on the street? Discriminant validity is the complement to convergent validity, as it seeks to confirm that a measure is not measuring things it should not be. Are there sufficient differences between an IQ test and a personality test that they are not just measuring the ability to take a survey? Are all measures derived from 311 highly correlated because they reflect the underlying tendency of a neighborhood to report not just physical disorder but anything?
Both statistical and non-statistical techniques are necessary for developing valid measures. We have already begun to practice the non-statistical ones and will continue to do so. Statistical techniques for validity typically entail correlation tests and related analyses. Section 6.7.2 will reference these in a superficial way as we work through our validation of the 311 data, but we will learn more about conducting them in Chapter 10. For now, though, it is important to practice thinking about what a measure should correlate with as well as what it should not correlate with.
What We Did: Disentangling Physical Disorder from Reporting Tendencies
My colleagues and I faced an intriguing challenge. The 311 records were clearly a reflection of both physical disorder and the tendency of residents to report said physical disorder. To illustrate, in communities where residents were not inclined to make reports, an issue might sit unnoted for a lengthy period, or even indefinitely, creating a gap in the database. Meanwhile, neighborhoods with very vigilant residents might even generate multiple reports for a single issue, exaggerating the prevalence of disorder. Thus, we needed to find a way to separate physical disorder from the tendency to report issues, thereby measuring both things. Otherwise we would not be able to measure either of them.
This section describes the four steps my colleagues and I took to establish a set of validated, 311-based measures of physical disorder that account for the bias introduced by reporting tendencies. As you might imagine, this was a rather extensive effort, and if you are interested in a more in-depth description of all the methods used they are available in another book I wrote called The Urban Commons (O’Brien 2018). Also, it is important to note that not all validation efforts need be this extensive, so please do not let it intimidate you from wanting to undertake your own validation exercises. Instead, look at the various steps taken here as parts of a menu of options for establishing validity.
Step 1: Assaying Disorder and Reporting
Our first step was to measure physical disorder and the tendency to report issues objectively. To accomplish this, I recruited a team of students to conduct audits in approximately half of Boston’s neighborhoods. We identified 244 street light outages and quantified the level of loose garbage on every street. Meanwhile, the City of Boston’s Public Works Department assessed the quality of all of the city’s sidewalks. We used the level of garbage to map objective levels of physical disorder. We then cross-referenced the street light outages and sidewalk assessments with 311 reports. This gave us estimates of the likelihood of communities to report these types of issues. We found, indeed, that this tendency varied considerably across neighborhoods.
Step 2: Estimating Civic Response Rate from 311 Reports
We need the civic response rate to adjust for biases in any measure of physical disorder we might develop. Assessing the civic response rate through a neighborhood audit is useful in this process but using it to adjust our measures is only a temporary solution. Eventually variation in the civic response rate will shift, with some places becoming more responsive and others less so. We want to be able to adjust for the civic response rate repeatedly using only the information generated by the 311 system. We must then isolate relevant content from the database, this time reflective of civic response rate.
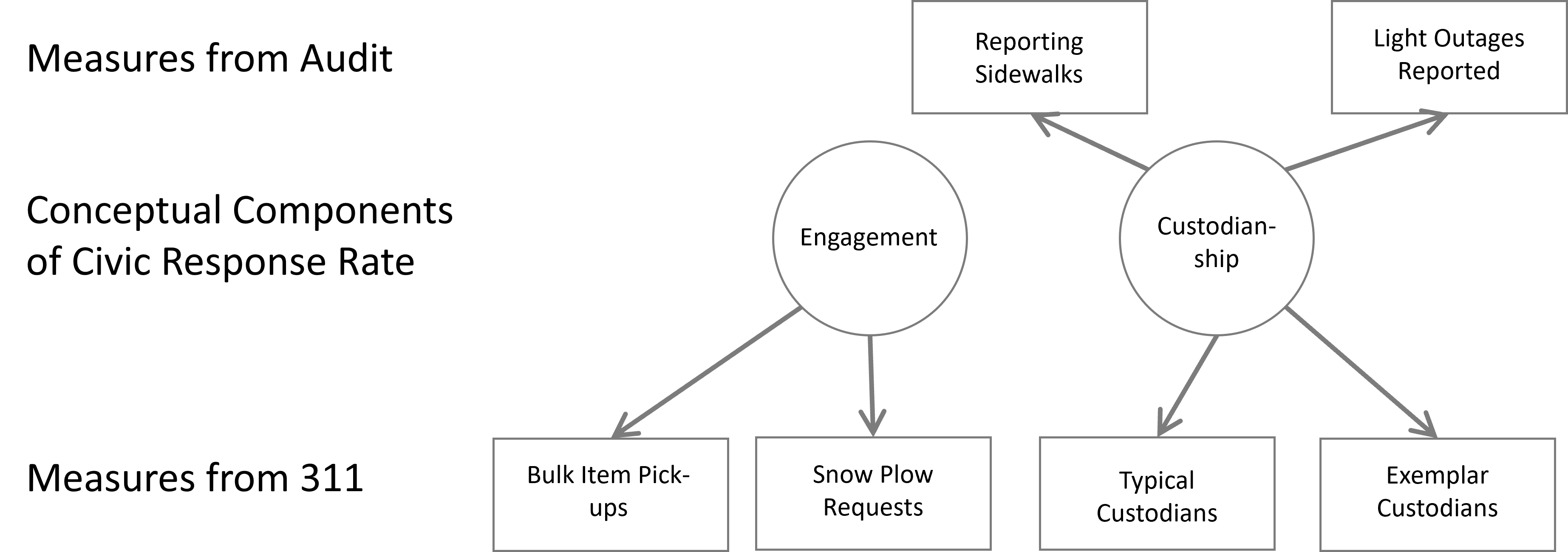
With that goal in mind, what goes into the civic response rate? We proposed two different elements. First was engagement, or knowledge of 311 and the willingness to use it. The second was custodianship, or the motivation to take responsibility for issues in the public space. Each of these is necessary for reporting a public issue: without the former, a custodian would not know what action to take; without the latter, someone with knowledge of the 311 system would have no motivation to use it.
This gave us two latent constructs for which we needed to develop manifest variables, as diagrammed in Figure 6.7. For engagement, these included: the proportion of neighborhood residents with an account; requests for the pickup of bulk trash items, the need for which would presumably be even across the city; and requests of snowplows during a snowstorm, being that a snowstorm hits the entire city (though controlling for certain infrastructural characteristics, like road length and dead ends). For custodianship, we identified a subset of 59 case types that reflect issues in the public domain, including many (but not all) of the case types regarding physical disorder as well as instances of natural deterioration, like street light outages. We then identified user accounts that had reported at least one of these cases. Further, we noted that a small fraction of these “custodians” made three or more reports in a year (~10%), whom we referred to as “exemplars.” We then created two manifest variables for custodianship by tabulating the number of “typical custodians” and “exemplars” in a neighborhood. Presumably neighborhoods with more of either of these groups would report public issues more often and more quickly.
We analyzed these metrics in combination with our objective measures of the civic response rate from the streetlight and sidewalk audits. This revealed that measures from the audits were only associated with our 311-derived measures of custodianship. That is to say, our objective measure of the civic response rate was more specifically an objective measure of custodianship, based on the convergent validity of these independent manifest variables.
Step 3: Calibrating the Adjustment Factor
At this point we have established that there is bias in reporting, created by differences in custodianship across neighborhoods. We might use our measures of custodianship then as a volume knob to balance out regional differences in custodianship. Where custodianship is lower, we can “turn up the volume” on the raw number of reports of physical disorder, assuming that some issues are going unreported. Where custodianship is higher, we need to turn down the volume to temper outstanding vigilance. Deciding just how much to adjust by, however, requires its own additional analysis. In short, we examined how well the measures of street garbage that we collected in-person predicted the prevalence of physical disorder reports made to 311 . We then assessed how well a consideration of the measures of custodianship could strengthen this relationship. The result told us just how much we needed to adjust. Interestingly, it turned out that disorder in public spaces needed substantial adjustment, but disorder in private spaces did not.
Step 4: Confirming Convergent Validity
We now have a measure of physical disorder that has been adjusted for each neighborhood’s level of custodianship. But how do we know if it is correct? We decided to check its correlations with a handful of neighborhood indicators traditionally associated with physical disorder and blight, including: median income, homeownership, density of minority population, perceived physical disorder from a resident survey, and reports of gun violence made through 911. We found that our newly developed measures of private neglect and public denigration had many of the anticipated relationships. As noted, this act of checking correlations with external measures is often a key step in establishing convergent validity.
Summary of Establishing Validity with 311
We have now walked through the four steps that my colleagues and I went through to validate our measures of physical disorder. Again, this was an extensive effort and not every validity exercise requires quite so much work. That said, there are a number of tools and lessons that you might take away from it, including:
- Reasoning through content validity of both the desired measure and the sources of bias from which it suffers;
- Sourcing external data to assess convergent and discriminant validity;
- Identifying other variables that should correlate with your measure if it is valid;
- The potential to generate not one but two interesting sets of measures, one of which being the source of bias itself.
Regarding the last point, in the current case physical disorder was the well-established metric we wanted to replicate with big data, but custodianship turned out to be the original insight that revealed much about how 311 systems actually work as collaborations between government and the public. Consequently, the former has been used as a tracking metric and a variable in studies on criminology, which is how it has often been used in the past. The latter became the basis for an entire book titled The Urban Commons (O’Brien 2018) and has added a new dimension to the study of neighborhoods.
Summary
This chapter has illustrated the challenges presented by naturally occurring data and the tools available for solving them by working through the development of measures of physical disorder (and custodianship) from 311 records. We have focused entirely on conceptual skills without even opening R or a single data set. These include being able to:
- Articulate the missing ingredients of naturally occurring data:
- Identify the desired unit of analysis from the schema of a data set;
- Isolate content relevant to a desired measure using the latent construct model;
- Identify potential sources of bias in a data set and develop a strategy for addressing them to establish validity.
As noted at the outset, we will put these conceptual skills to good use in the next chapter as we gain the complementary technical skills. We will then be able to develop new aggregate measures for our desired unit of analysis.
Exercises
Problem Set
- Define the following terms and their relevance to developing novel measures from naturally occurring data.
- Schema
- Content validity
- Convergent validity
- Latent construct
- Manifest variable
- Propose one or more potential sources of bias you might expect for each of the following measures.
- Quality of sounds and smells street-by-street as drawn from Twitter postings.
- Political attitudes as drawn from Facebook postings.
- The median rent of apartments as drawn from Craigslist postings.
- The investment in a neighborhood by landowners as drawn from building permit applications.
- Social connectivity as drawn from cell phone records
Exploratory Data Assignment
Working with a data set of your choice:
- Propose at least one latent construct that you would like to measure with your data set and the unit of analysis for which you would want to measure it. Be sure to confirm that this unit of analysis is available from the schema of the data set.
- Describe how this construct is interesting, and at least one manifest variable for measuring it. Use the latent construct modeling notation from this week to bring it across.
- Suggest any potential sources of bias that might complicate the development and interpretation of the measure(s).
- Note: Your manifest variable can be an idea at this point. You will figure out how to code it in R in the coming chapters.
Anderson, Chris. 2008.
“The End of Theory: The Data Deluge Makes the Scientific Method Obsolete.” WIRED.
http://www.wired.com/2008/06/pb-theory/.
O’Brien, Daniel T. 2018. The Urban Commons. Cambridge, MA: Harvard University Press.
Pigliucci, Massimo. 2009. “The End of Theory in Science?” EMBO Reports 10 (6): 534.